Web scraping merupakan salah satu metode untuk melakukan akuisisi data dari website publik. Pada artikel sebelumnya penulis pernah menyinggung mengenai web scraping dan pada artikel ini penulis akan membahas secara komprehensif bagaimana cara membuat sebuah web scraper untuk mendapatkan data dari sebuah website.
Pada artikel ini kita akan membuat sebuah web scraper untuk mengambil data listing perumahan di daerah Bogor dari laman Rumah123.com. Data dari scraper ini juga akan kita gunakan pada artikel yang akan datang, jadi jangan lupa diikuti ya!
Oke sebelum kita mulai, apa sih web scraping itu?
Web scraping secara umum adalah proses ekstraksi data dari suatu website. Dalam konteks akuisisi data, web scraping merujuk pada proses mengekstrak data misalnya listing dari suatu website secara otomatis.
Terdapat dua kata kunci yang perlu kita pahami, website dan scraping.
- Website secara umum kita kenal adalah halaman-halaman yang bisa kita akses melalui suatu domain. Misalnya website Kodesiana.com memiliki banyak artikel dan halaman-halaman seperti kategori dan pencarian
- Scraping merupakan proses ekstraksi data yang dalam konteks ini ekstraksi dari suatu website
Selain scraping ada istilah lain yang perlu kita tahu yaitu crawling. Crawling merupakan proses menjelajahi tautan atau link pada suatu halaman website. Teman-teman tentunya perlu klik pada tautan ke artikel ini baik dari halaman beranda maupun dari langganan email, bukan? Tidak mungkin teman-teman mengingat URL artikel ini dan mengetiknya manual di peramban/browser. Tautan-tautan atau link ini disebut sebagai hyperlink.

Nah sekarang kita tahu bahwa web scraping merupakan proses ekstraksi data dari website secara otomatis dengan cara menjelajahi tautan atau link pada laman website, pertanyaan selanjutnya adalah bagaimana proses ekstraksi tersebut terjadi?
Sekarang coba kita bayangkan proses scraping secara manual. Misalnya penulis ingin mencari tahu harga “Samsung Galaxy Tab S6 Lite” di Tokopedia, penulis akan melakukan:
- Membuat sebuah spreadsheet untuk mencatat data
- Membuat nama-nama kolom misalnya nama toko, jumlah terjual, rating, dan harga
- Penulis membuka laman Tokopedia, kemudian melakukan pencarian dengan kata kunci “samsung galaxy tab s6 lite”
- Akan muncul hasil pencarian berupa grid yang berisikan foto, judul, nama toko, rating, dan jumlah terjual
- Berdasarkan data barang yang ada, penulis akan catat satu per satu data dari hasil pencarian ke spreadsheet
- Setelah semua barang dicatat, lanjut ke halaman kedua
- Lakukan proses 5-6 hingga didapatkan jumlah data yang cukup
Nah daripada melakukan proses tersebut secara manual yang pastinya akan memakan banyak waktu, kita bisa mengotomatisasi proses ekstraksi data tersebut dengan cara membuat web scraper. Proses yang sama akan kita implementasi dengan menggunakan pemrograman, pada kasus ini kita akan belajar membuat scraper menggunakan bahasa pemrograman Python dan library scrapy.
Tapi tunggu dulu!
Berbeda dengan manusia yang bisa mengidentifikasi informasi secara visual, komputer menginterpretasi sebuah website berdasarkan strukturnya. Lalu bagaimana struktur sebuah website itu?
Fundamental Website🌏
Sebuah website tentunya perlu dibuat menggunakan koding dan teman-teman pasti sudah familiar dengan istilah HTML, CSS, dan JS. Bagi yang belum familiar, kita akan sedikit bahas kembali mengenai tiga fundamental website ini.
Hypertext Markup Language (HTML) 🧱
Hypertext Markup Language (HTML) mendefinisikan struktur dan konten sebuah halaman website. Sama seperti kita membuat sebuah karya tulis ilmiah yang biasanya berisi beberapa bab seperti pendahuluan yang berisi latar belakang, rumusan masalah, dan tujuan penelitian; pada sebuah website struktur dan kontennya didefinisikan menggunakan tag HTML.
Konten pada suatu website pasti berada di antara sebuah elemen, yang terdiri atas opening tag, konten, dan closing tag.

Pada konteks web scraping, kita menginginkan konten yang berada diantara opening dan closing tag. Secara umum sebuah website akan memiliki sangat banyak tag yang digunakan untuk memberikan struktur pada halaman website, sehingga hal ini juga menjadi tantangan tersendiri dalam membuat sebuah web scraper, yaitu bagaimana cara mendapatkan data yang kita mau dan membuang tag yang tidak diperlukan.
Cascading Style Sheets (CSS) 💄
Jika HTML bertanggung jawab untuk memberikan struktur dan konten pada halaman website, Cascading Style Sheets (CSS) bertugas untuk memberikan gaya atau style pada halaman website. Jika HTML adalah tembok rumah, maka CSS adalah cat rumah yang memberikan warna dan estetika.
Dalam praktiknya web developers akan menggunakan banyak CSS untuk membuat tampilan yang estetik dan umumnya juga, gaya atau style ini akan dikelompokkan menjadi kelas-kelas yang nantinya bisa diterapkan ke elemen-elemen HTML sesuai kebutuhan.
Contoh kode CSS:
| |
Secara umum style dapat diterapkan ke elemen HTML dengan dua cara,
- Menerapkan style ke tag HTML, contohnya semua tag
h1akan memiliki gaya font bold - Membuat sebuah kelas style, contohnya
merah. Ketika sebuah elemen memiliki atribut kelasmerah, maka teksnya akan menjadi warna merah
JavaScript (JS) 🎠
Bagian terakhir dari fundamental website adalah JavaScript. Setelah kita mempunyai struktur, konten, dan gaya, maka komponen terakhir yang kita perlukan adalah fungsi interaktif dalam halaman website (interactivity). Jika HTML dan CSS adalah markup, maka JavaScript adalah programming language.
HTML/CSS juga bahasa pemrograman!!!🤬 Say what you want, but is HTML/CSS turing complete? No?
Contohnya adalah kolom pencarian artikel Kodesiana.com. Ketika teman-teman menginputkan teks pada kolom pencarian, teman-teman akan mendapatkan hasil pencarian secara real-time. Pada kasus ini, kolom pencarian dibuat menggunakan HTML (elemen input), kemudian diberikan gaya corner-radius menggunakan CSS, dan interaksi ketika pengguna menuliskan teks pada kolom input maka akan dilakukan pencarian.
Dalam konteks web scraping, kita biasanya tidak perlu mengekstrak data dari kode JavaScript karena tentu saja, ini adalah kode untuk interaksi, bukan konten. Konten hanya ada dalam HTML*.
*Kita akan bahas mengenai konsep ini pada subbab terakhir artikel ini karena ada beberapa kasus tersendiri di mana JavaScript ini diperlukan.
Contoh Laman Sederhana📃
Nah kita sudah bahas konsep dasar sebuah website, sekarang kita akan coba lihat contoh kode sebuah halaman web. Pada contoh ini kita akan lihat sebuah kode HTML dan CSS sederhana tanpa JS.
| |
Jika teman-teman salin dan simpan kode di atas dalam file .html, teman-teman akan melihat halaman sebagai berikut (gambar mungkin berbeda).
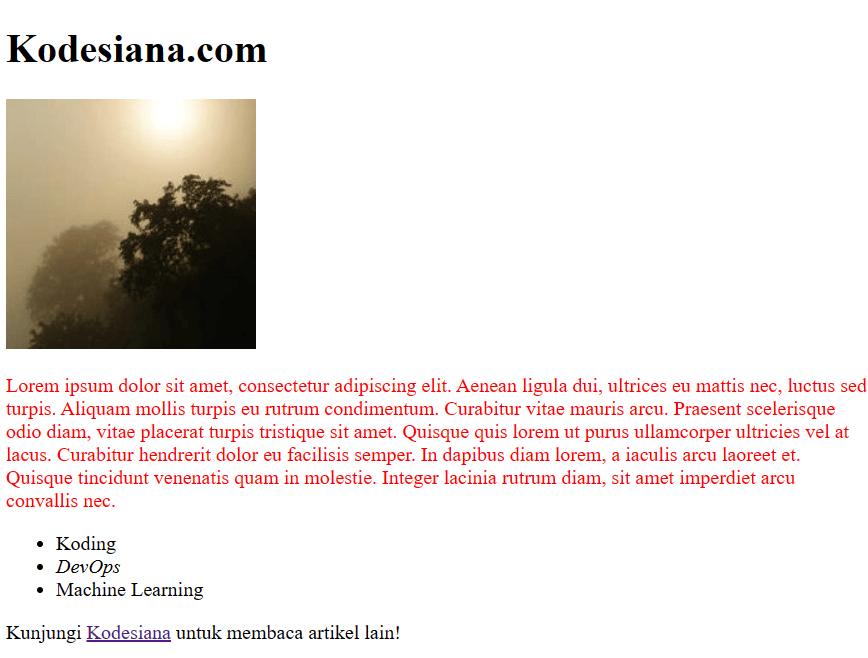
Laman web sederhana. Sumber: Penulis
Jika kita amati antara kode dan visual halaman di peramban, terdapat beberapa elemen HTML yang kita gunakan,
<style>, blok elemen ini digunakan untuk mendefinisikan kode CSS (biasanya kode CSS disimpan pada berkas .css menggunakan elemen<link>)<h1>, elemen ini menyatakan heading atau judul/subbab<img>, elemen ini digunakan untuk menampilkan gambar yang berlokasi di atributsrc<p>, elemen ini digunakan untuk menyatakan teks paragraf. Perlu diingat sering kali karena alasan struktur dan estetika, teks bisa saja ditempatkan pada elemen seperti<span>atau<i><ul>(kepanjangannya unordered list) berisi<li>(list item), elemen ini digunakan untuk membuat bullet points. Pada contoh ini terjadi nesting atau penggunaan elemen HTML di dalam elemen lain
Nah dari kelima contoh elemen ini kita sudah memiliki sedikit gambaran bagaimana sebuah website dibangun. Tahap selanjutnya adalah, bagaimana cara kita bisa memilih tag mana yang mengandung data yang ingin kita simpan dan bagaimana cara mengekstrak datanya?
DevTools atau Inspector💻
Cara paling mudah untuk menginspeksi elemen-elemen sebuah halaman website adalah dengan menggunakan DevTools atau Inspector yang disediakan oleh peramban. Pada contoh ini penulis akan menggunakan Microsoft Edge DevTools untuk melakukan inspeksi. Jangan khawatir, teman-teman bisa menggunakan peramban apapun seperti Firefox, Chrome, Safari, Brave, Opera dan lainnya karena fitur ini pasti ada di semua peramban.
Cara mengaksesnya adalah klik kanan pada halaman web, kemudian pilih Inspect.
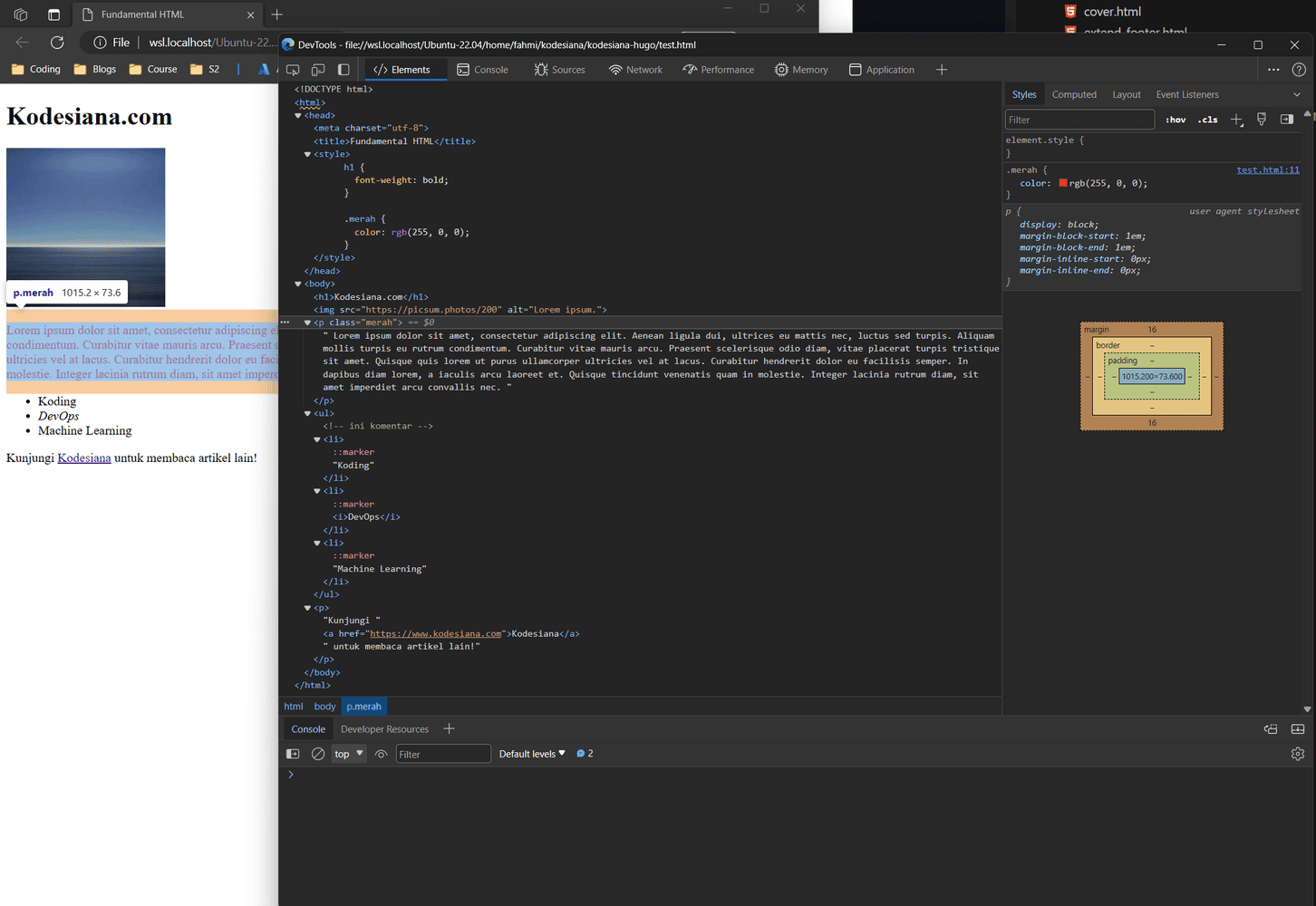
Chromium DevTools. Sumber: Penulis
DevTools berfungsi untuk membantu web developer untuk debugging halaman web-nya. DevTools menyediakan berbagai tools seperti Element Inspector dan Computed Styles untuk membantu kita membuat selector.
Selectors🔍
Apa itu selector?
Selector adalah suatu aturan untuk menargetkan elemen HTML pada Document Object Model (DOM). Pada tampilan Inspect Elements di atas kita bisa lihat kode HTML dari halaman yang kita buka dan keseluruhan struktur HTML ini disebut sebagai DOM.
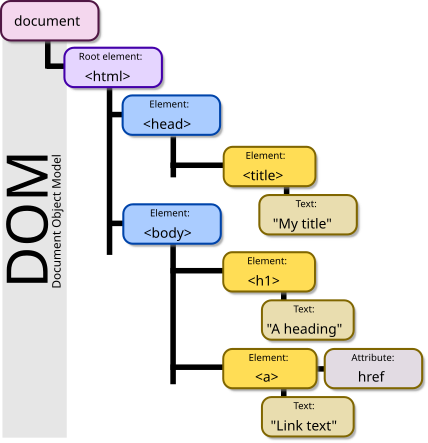
Document Object Model (DOM). Sumber: Birger Eriksson dari Wikimedia Commons
Secara umum terdapat dua cara yang lazim digunakan untuk memilih elemen pada DOM, yaitu CSS selector dan XPath. Pada jendela DevTools, buka kolom pencarian dengan cara tekan CTRL+F.
Beberapa contoh sintaks CSS selector:
| Selector | Contoh | Keterangan |
|---|---|---|
.class | .merah | Memilih semua elemen dengan class="merah" |
.class1.class2 | .teks.merah | Memilih semua elemen dengan atribut class yang berisi teks dan merah |
#id | #input_nama | Memilih elemen dengan id="input_nama" |
element element | ul li | Memilih semua <li> di dalam <ul> |
[attribute*=value] | [href*="google.com"] | Memilih semua elemen yang memiliki atribut href yang berisi kata “google.com”. Aturan ini bisa ditambah prefix elemen untuk memilih berdasarkan elemen dan atribut |
Beberapa contoh sintaks XPath:
| Selector | Contoh | Keterangan |
|---|---|---|
/ | /body/p | Memilih elemen <p> dari relatif terhadap root DOM |
// | //p | Memilih semua elemen dengan tag <p> di manapun lokasinya dalam DOM |
//element/* | //ul/* | Memilih semua elemen yang berada di dalam <ul> di manapun lokasinya di dalam DOM |
//element/elemen | //ul/li | Memilih semua elemen <li> yang berada di dalam <ul> di manapun lokasinya dalam DOM |
//elemen[@attribute=value] | //p[@class="merah"] | Memilih semua elemen <p> dengan atribut class="merah" di manapun lokasinya dalam DOM |
Beberapa contoh pengaplikasian CSS selector pada halaman HTML yang sudah dibuat sebelumnya:
Contoh 1: pencarian berdasarkan tag HTML <img>
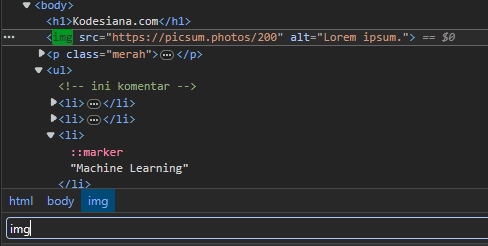
Contoh 2: pencarian berdasarkan tag <p> yang memiliki atribut class yang berisi kata “merah”
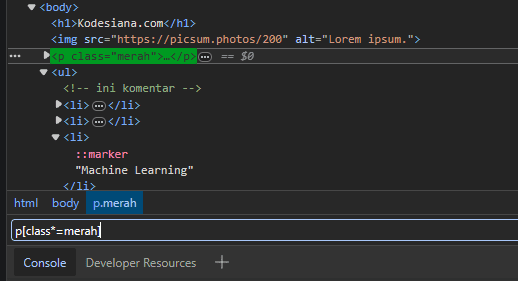
Jangan lupa latihan untuk membuat selector 🫡
Dengan modal pengetahuan selector ini, kita akan coba membuat scraper menggunakan Scrapy untuk menunduh data harga rumah dari website Rumah123.com. Pada artikel ini penulis akan fokus menggunakan XPath saja karena penulis lebih nyaman menggunakan XPath.
Scrapy⛏️
Scrapy merupakan framework Python untuk melakukan web scraping. Scrapy mampu melakukan pencarian menggunakan CSS selector dan XPath. Selain itu Scrapy juga mendukung pemrosesan parallel dan pipeline untuk mengolah data scraping secara real time sebelum disimpan.
Komponen Scrapy🛒
Scrapy memiliki setidaknya lima komponen penting yang perlu kita pahami untuk dapat membuat sebuah web scraper.
Spider
Spider merupakan komponen utama dalam Scrapy yang berfungsi untuk mengatur bagaimana proses scraping dilakukan. Pada spider kita bisa mengatur URL apa saja yang akan di-crawl dan bagaimana proses scraping dilakukan untuk setiap URL yang di-crawl hingga menghasilkan data yang diinginkan.
Selectors
Selectors adalah kelas yang menyediakan fungsi pencarian menggunakan CSS selector dan XPath. Secara umum kita bisa mengakses selector ketika spider berhasil membaca sebuah halaman.
Items
Items adalah sebuah kelas atau dict yang menampung output data dari proses scraping. Scrapy bisa menerima item berupa dict atau kelas turunan dari scrapy.item.Item. Jika kita menggunakan kelas turunannya, kita bisa menggunakan fungsi pemrosesan data yang lebih komprehensif seperti item loaders dan item pipeline, tetapi pada artikel ini kita akan menggunakan dict sederhana untuk mempersingkat kode yang perlu dibuat.
Feed export
Ketika proses scraping menghasilkan item, tahap selanjutnya adalah menyimpan items tersebut ke sebuah file menggunakan feed exporter. Exporter bawaan dari Scrapy adalah JSON, JSON lines, CSV, dan XML.
Shell
Scrapy shell merupakan layanan interaktif untuk menguji kode scraping secara real time. Pada pembahasan sebelumnya kita bisa menggunakan DevTools atau Inspector untuk menguji pencarian menggunakan CSS selector dan XPath, tetapi kadang sintaks pencarian yang kita buat tidak selalu bisa digunakan di Scrapy karena perbedaan struktur HTML (pembahasan selanjutnya di subbab Dynamic JS Content), maka dari itu kita bisa mencoba kode Scrapy secara real time menggunakan scrapy shell.
Penulis biasanya mengguanakan DevTools untuk membuat sintaks pencarian, kemudian menggunakan scrapy shell untuk mencoba mengeksekusi pencarian sebelum akhirnya dilakukan scraping secara penuh.
Nah sampai di sini kita sudah membahas banyak mengenai teori dari framework scrapy, selanjutnya kita akan membuat web scraper untuk laman Rumah123 dan kita akan mengekstrak informasi listing rumah di daerah Bogor.
Membuat Spider🗃️
Tahap pertama dari membuat web scraper adalah menyiapkan proyek terlebih dahulu. Anda bisa menggunakan Python atau Anaconda untuk membuat virtual environment. Jalankan perintah berikut untuk meng-install scrapy.
pip install scrapy atau conda install scrapy
Tunggu hingga proses install selesai, kemudian jalankan perintah berikut untuk membuat project baru.
| |
Jika proses ini berhasil, kita akan mendapatkan folder baru yaitu harga_rumah dengan isi direktori sebagai berikut.
| |
Kita akan bahas mengenai struktur ini pada bagian selanjutnya.
Setelah kita memiliki folder proyek scraping, tahap selanjutnya adalah membuat spider baru.
| |
Sampai di tahap ini seharusnya kita akan mendapatkan file rumah123.py di dalam folder spiders. Kita akan membuat kode scraper kita pada file ini.
Konfigurasi Dasar Spider
Sebelum kita lanjut membuat kode untuk melakukan scraping, ada beberapa konfigurasi yang perlu kita atur. Buka file settings.py kemudian isikan dengan kode berikut.
Sebagian besar kode berikut sudah ada dalam file
settings.py, cukup ganti bagian yang sesuai saja, tidak perlu di ganti semuanya.
| |
Penjelasan kode:
BOT_NAME,SPIDER_MODULES,NEWSPIDER_MODULEmerupakan konfigurasi bawaanscrapyuntuk mengidentifikasi nama bot dan lokasi spider. Jangan ubah bagian iniUSER_AGENTmengatur User-Agent yang akan digunakan ketika melakukan scraping. Secara umum User-Agent digunakan untuk mengidentifikasi jenis klien yang mengakses server. Pada contoh ini kita menggunakan User-Agent Microsoft Edge sehingga server akan merekam aktivitas scraping seperti dilakukan oleh EdgeROBOTSTXT_OBEYmerupakan fitur Scrapy untuk mematuhi aturan darirobots.txt. Robots.txt merupakan standar yang menyatakan apa saja URL yang boleh dicari oleh bot. Secara umum kita bisa mengabaikan robots.txt pada kasus tertentu misalnya ingin melakukan scraping pada halaman yang perlu loginCOOKIES_ENABLEDmengaktifkan kuki untuk setiap request yang dilakukan oleh scraperCONCURRENT_REQUESTmenentukan berapa banyak worker yang akan melakukan request ke server. Pada kasus ini kita menggunakan nilai 1 agar proses scraping hanya dilakukan satu persatu. Kita bisa meningkatkan nilai ini tetapi ada kemungkinan server akan memblokir scraper kita (pelajari lebih lanjut di subbab CAPTCHA)RETRY_TIMESmenentukan berapa kali scraper bisa melakukan percobaan scraping kembali jika proses scraping gagal, misalnya karena masalah koneksi internet atau lainnyaDOWNLOAD_DELAYmenentukan berapa lama waktu tunggu antara satu dan request lainnya. Misalnya jika CONCURRENT_REQUEST=1 dan DOWNLOAD_DELAY=3, berarti setelah proses scraping selesai, Scrapy akan menunggu tiga detik sebelum melanjutkan scraping halaman selanjutnyaSPIDER_MIDDLEWARES,DOWNLOADER_MIDDLEWARESmengatur middleware yang akan digunakan oleh spider. Middleware adalah kode yang dieksekusi ketika proses crawl dan berfungsi untuk mengubah, menambah, dan mengatur proses crawl. Pada kasus ini kita tidak menggunakan middleware tambahanCLOSESPIDER_ERRORCOUNT,EXTENSIONSmengaktifkan integrasi denganCloseSpider, ekstensi ini berfungsi untuk menghentikan proses scraping apabila terjadi tiga kali errorAUTOTHROTTLE_konfigurasi ekstensiAutoThrottle. Ekstensi ini berfungsi untuk mengurangi kecepatan scraping ketika server mengirimkan error. Intinya adalah ekstensi ini untuk mencegah server memblokir aktivitas scraping karena indikasi kecepatan akses yang terlalu cepatREQUEST_FINGERPRINTER_IMPLEMENTATION,TWISTED_REACTORkonfigurasi internal Scrapy. Jangan diubahFEED_EXPORT_ENCODING,FEEDSmengatur output feed atau lokasi output data yang di-scraping. Pada kasus ini kita akan menyimpan hasil scraping pada filerumah123.jsondengan format JSON lines, artinya satu baris JSON untuk setiap data
Sampai di sini kita sudah mengatur behavior spider yang nantinya akan kita gunakan untuk melakukan scraping. Tahap selanjutnya kita akan membuat spider untuk mengekstrak data dari halaman menggunakan XPath.
Mengekstrak Data dari Website📌
Pada tahap sebelumnya kita sudah membuat spider dengan nama file rumah123.py. Sekarang kita akan membuat kode untuk mengekstrak data dari halaman Rumah123.com. Sebelum itu, file rumah123.py akan memiliki kode berikut.
| |
Potongan kode di atas menjelaskan bahwa kita akan melakukan scraping dimulai dari https://rumah123.com dan proses scraping hanya dibolehkan untuk domain rumah123.com. Hal ini diperlukan untuk membatasi agar scraper tidak menjelajahi halaman yang tidak relevan.
Catatan: Website pasti akan selalu diperbarui. Kita sudah bisa melihat bagaimana Facebook, Google, Instagram, Twitter, dan berbagai platform lain berubah setiap tahunnya. Perubahan-perubahan ini tentunya memerlukan perubahan kode HTML, CSS, dan JS yang berarti setiap kali ada perubahan pada suatu halaman website, sekecil apapun, maka bisa jadi scraper yang sudah kita buat bisa menjadi tidak bekerja secara tiba-tiba. Jika ada perubahan, kita harus menyesuaikan kembali kode scraper kita.
Tahap pertama yang akan kita lakukan untuk membuat scraper adalah mengimpor library yang akan kita gunakan,
| |
Selanjutnya kita akan mengatur start_url. Variabel ini berfungsi untuk mengatur URL awal yang akan di-crawl oleh scrapy. Bagaimana cara kita mengetahui URL awal untuk di-crawl? Kita perlu membuka halaman yang akan kita scrape.
Pada kasus ini kita akan mencari properti di daerah Bogor. URL untuk halaman listing ini adalah https://www.rumah123.com/jual/bogor/rumah.
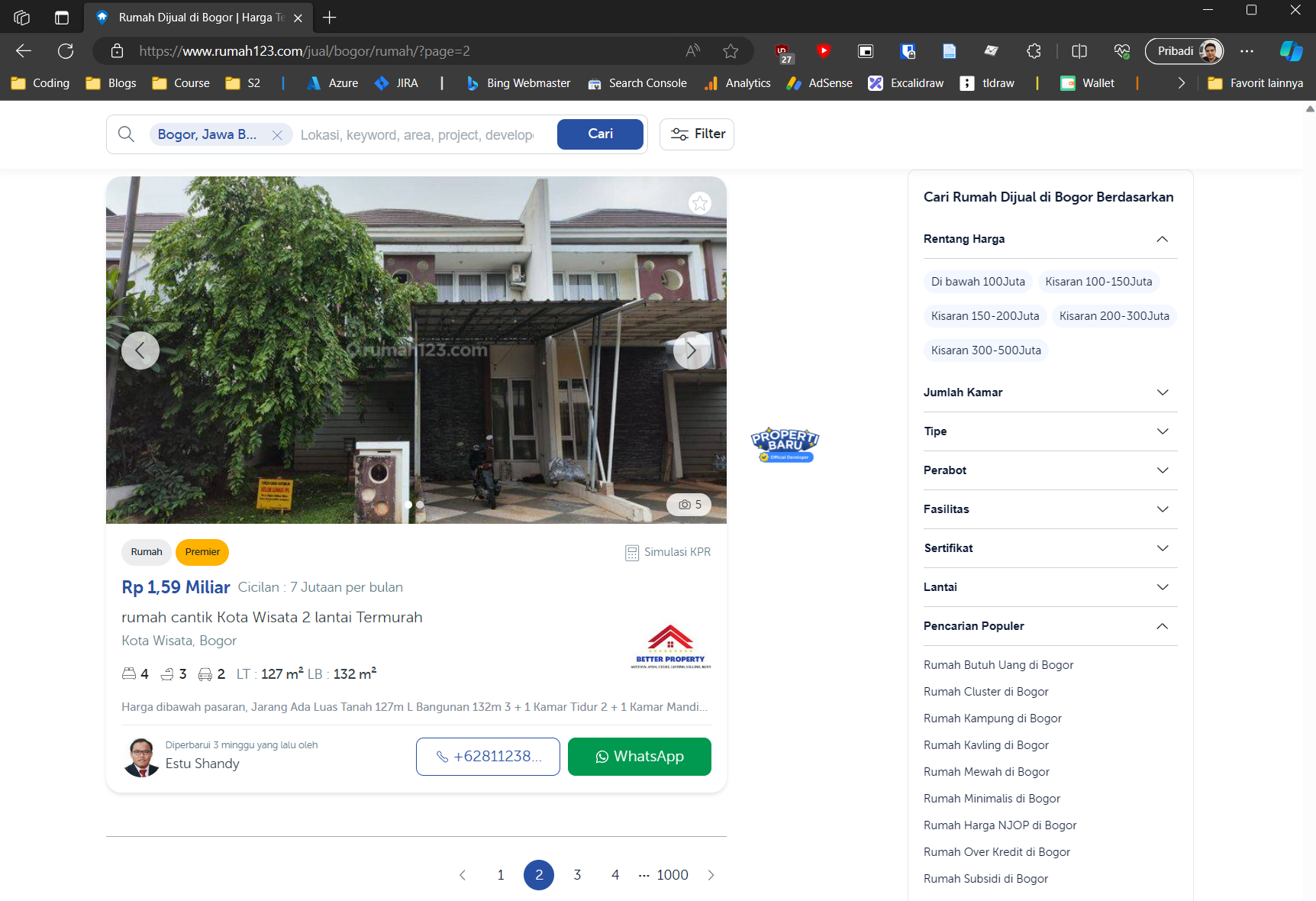
Sumber: Penulis.
Sekarang kita coba perhatikan perubahan URl ketika kita membuka halaman kedua. Ketika kita buka halaman kedua, URL berubah menjadi https://www.rumah123.com/jual/bogor/rumah/?page=2. Sekarang coba buka halaman ketiga, apakah query params berubah menjadi page=3?
Sekarang kita sudah memiliki pola bagaimana Rumah123.com melakukan paginasi. Sekarang kita bisa menggunakan fakta ini untuk mengatur URL awal scraping. Pada kasus ini kita akan melakukan scraping pada 500 halaman listing.
Ubah start_url menjadi:
| |
Sekarang scrapy akan melakukan scraping pada URL berikut.
- https://www.rumah123.com/jual/bogor/rumah/?page=1
- https://www.rumah123.com/jual/bogor/rumah/?page=2
- …
- https://www.rumah123.com/jual/bogor/rumah/?page=499
Setelah kita mengatur URL awal yang akan kita scrape, tahap selanjutnya akan mengekstrak setiap properti yang muncul pada halaman listing.
Implementasi Fungsi parse
Fungsi parse pada scrapy akan dieksekusi setiap kali scrapy selesai melakukan crawling pada suatu URL. Pada kasus ini kita sudah membuat daftar URL yang akan kita jelajahi, yaitu halaman listing properti. Tetapi informasi yang ditampilkan pada halaman ini tidak selengkap jika dibandingkan dengan kita membuka halaman detail properti.
Coba kita perhatikan informasi yang ada pada halaman detail properti.
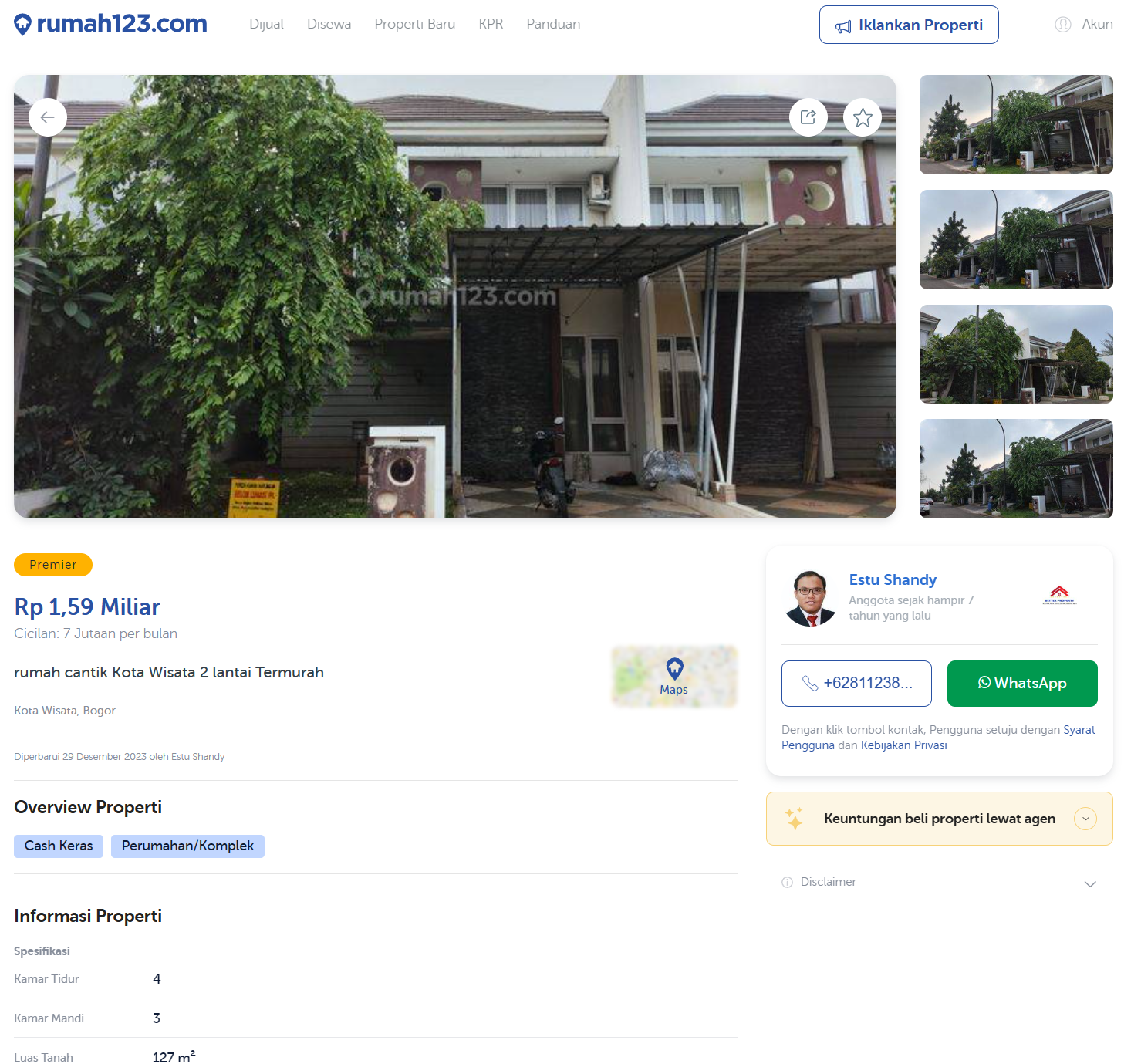
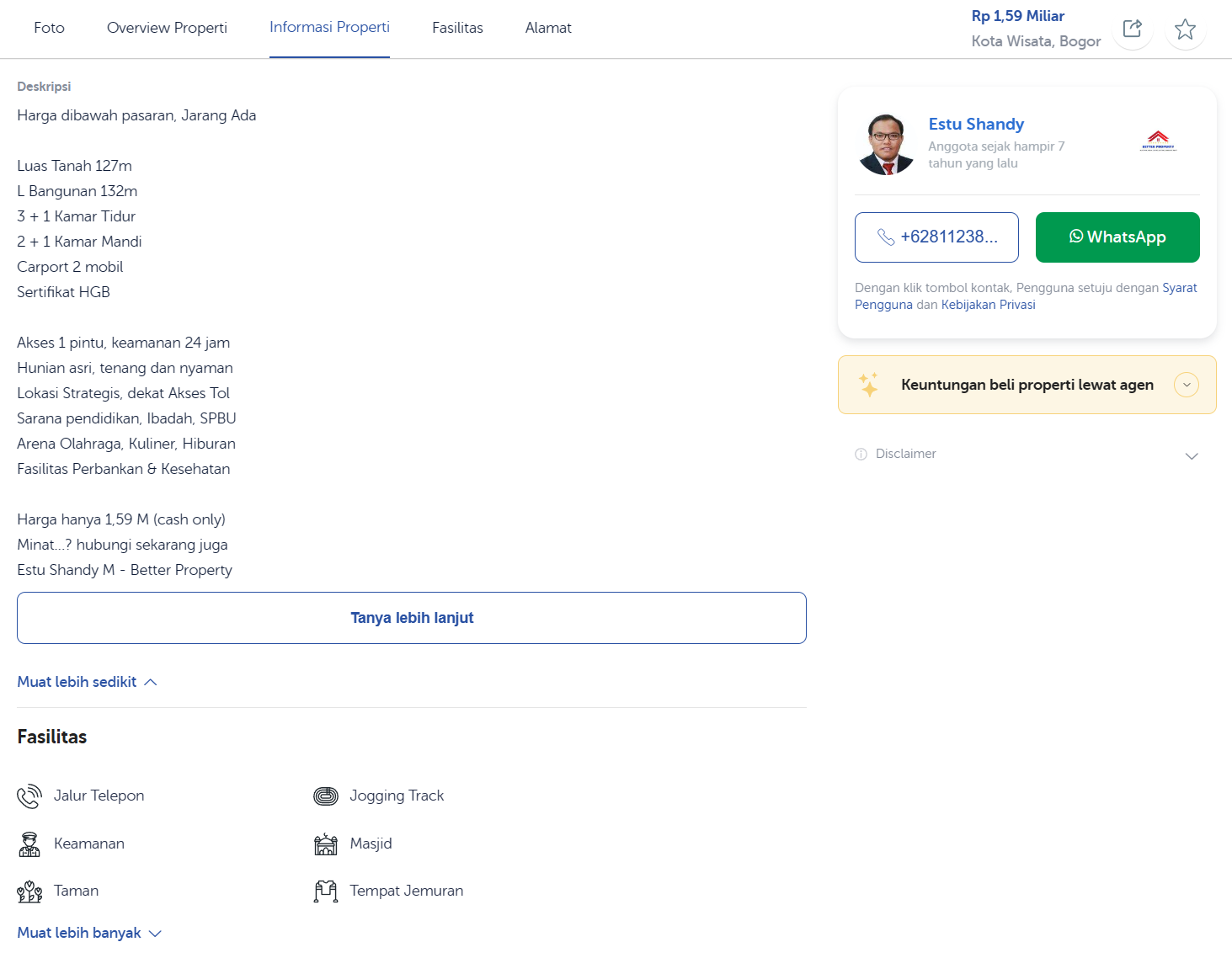
Sumber: Penulis
Berdasarkan contoh halaman detail properti ini, ada banyak informasi yang bisa kita ekstrak, misalnya:
- Harga dan cicilan
- Alamat
- Gambar properti
- Overview properti (Cash Keras, Perumahan/Komplek)
- Deskripsi
- Spesifikasi (kamar tidur, kamar mandi, dll.)
- Fasilitas (jalur telepon, keamanan, dll.)
- Agen properti
- Waktu terakhir kali properti diperbarui
Tentu masih ada informasi lain seperti lokasi maps, waktu diperbarui, dan lainnya yang bisa kita ekstrak, tetapi pada kasus ini kita akan coba mengekstrak informasi di atas dari halaman detail properti ini.
Untuk memudahkan kita mengekstrak informasi tersebut, kita akan memisahkan proses ekstraksi untuk setiap komponen tersebut menjadi fungsi-fungsi terpisah. Seperti yang sudah dijelaskan sebelumnya, kita perlu memerintahkan scrapy untuk meng-crawl halaman detail properti karena sementara ini kita baru meng-crawl halaman listing saja.
Pada file rumah123.py, tambahan kode berikut.
| |
Pada fungsi di atas kita menggunakan keyword yield menjadikan fungsi parse sebagai generator. Intinya adalah setiap kali scrapy melakukan crawl, jika kita mendeteksi halaman detail properti (ditandai dengan adanya kata /properti kecuali kata perumahan-baru) maka kita akan melakukan scraping dan mengembalikan dict yang berisi data.
Setelah itu akan dicari semua URL pada halaman dan kemudian dilakukan pengecekan kembali apakah URL tersebut adalah halaman detail properti, jika iya kita akan menggunakan fungsi response.follow() untuk menginstruksikan scrapy agar men-crawl URL tersebut.
Ekstrak ID Properti
Setiap data pasti memiliki sebuah ID atau kode unik yang mengidentifikasi satu objek dengan objek lainnya, seperti halnya NIK bersifat unik untuk semua penduduk di Indonesia. Tujuannya adalah agar nanti setelah proses scraping kita bisa mendeteksi duplikasi data meskipun scrapy sudah memiliki fitur deduplikasi URL (kadang ada yang lolos duplikasi). Pada kasus ini ID properti bisa kita ekstrak dari URL.
| |
Kita bisa menggunakan kode berikut untuk mengekstrak bagian terakhir dari URL.
| |
Fungsi os.path.normpath akan menormalisasi URL dengan menghapus karakter “/” terakhir pada URL dan fungsi os.path.basename akan mengembalikan segmen URL terakhir yang merupakan ID properti.
Ekstrak Harga
| |

Lokasi elemen yang mengandung harga. Sumber: Penulis.
Proses ekstraksi data harga terdiri atas tiga tahap,
- Mengekstrak harga menggunakan XPath, dari sini kita akan mendapatkan informasi harga berupa teks, misalnya “Rp 2,7 Miliar”
- Memecah teks berdasarkan spasi, kemudian mengambil nilai dan satuannya (miliar/juta)
- Mengonversi
stringmenjadifloatdan mengalikan dengan 1000 jika satuannya adalah miliar agar satuannya menjadi juta
Ekstrak Cicilan
| |
Proses ekstrak nilai cicilan ini tidak jauh berbeda dengan proses ekstrak harga properti, perbedaannya pada kasus ini kita punya informasi tambahan yaitu cicilan selalu dalam satuan juta, sehingga tidak perlu melakukan konversi skala satuan.
Selain itu, pada kasus ini juga nilai cicilan selalu dalam bentuk bilangan bulat, maka dari itu kita bisa menggunakan regular expression (regex) untuk memilih angka pada teks (\d artinya pilih semua digit/angka dan + artinya satu atau lebih karakter).
Ekstrak Gambar Properti
| |
Proses ekstraksi gambar dapat dilakukan dengan mudah juga, kita cukup mencari semua elemen <img> dan mengambil nilai atribut src. Tetapi tidak semua gambar perlu kita simpan karena gambar pada laman website bisa berupa logo, ikon, maupun gambar lain yang tidak relevan.
Maka dari itu kita akan memilih hanya gambar yang memiliki kata “customer” pada URL nya saja yang akan kita simpan.
Ekstrak Alamat
| |
Proses ekstraksi alamat dapat dilakukan dengan satu XPath saja.
Ekstrak Overview/Tags
| |
Proses ekstraksi overview atau tags juga dapat dilakukan dengan sangat mudah menggunakan XPath. Pada kasus ini kita juga akan menggunakan list comprehension untuk menghilangkan spasi di awal maupun di akhir teks menggunakan fungsi strip().
Ekstrak Deskripsi
| |
Pada proses ekstraksi deskripsi ini kita akan menggunakan fungsi following-sibling, gunanya adalah kita ingin memilih elemen yang merupakan sibling atau bersebelahan dengan elemen yang dipilih.
Contoh:
| |
Sintaks XPath //p[@class='listing-description-v2__title']/following-sibling::div/div/div/div/text() akan memilih elemen <p class="listing-description-v2__title">Deskripsi</p> sebagai acuan dan following-sibling akan memilih teks pada elemen div/div/div/div yang berisi teks deskripsi.
Karena elemen-elemen dalam tag <div> ini dipisahkan oleh tag <br>, maka scrapy akan memilih setiap teks dalam elemen <div> dan kita perlu menyatukan kembali teksnya menggunakan fungsi join(). Tag <br> berarti break atau alinea baru pada paragraf.
Ekstrak Spesifikasi Properti
| |
Proses ekstraksi spesifikasi properti ini sedikit lebih kompleks karena kita akan menggunakan dua selector berbeda untuk mengekstrak data spesifikasi. Spesifikasi properti pada laman terdapat dalam bentuk tabel atau spesifiknya key-value, misalnya kamar tidur=3.
Tahap pertama adalah melakukan pemilihan elemen menggunakan XPath //div[@class='listing-specification-v2__item'] untuk mengambil semua <div> yang mengandung spesifikasi. Kemudian XPath kedua ./span/text() digunakan untuk mengambil data di dalam <span> dan kemudian teks tersebut dimasukkan ke dalam dict dengan key adalah indeks pertama dan value adalah indeks kedua.
Ekstrak Fasilitas
| |
Proses ekstraksi ini dilakukan dua kali karena ternyata Rumah123 memiliki dua versi laman yang berbeda. Karena adanya dua versi <div> maka kita perlu melakukan scraping menggunakan dua XPath. Karena nilai kembalian dari fungsi getall() adalah list, kita bisa menggunakan operator + untuk menggabungkan kedua hasil scraping.
Ekstrak Agen Properti
| |
Bagian ini adalah bagian yang paling kompleks karena kita ingin mengekstrak banyak informasi dalam satu fungsi.
Tahap pertama adalah mengekstrak informasi host, di sini kita menggunakan urlparse untuk membuat host. Tahap selanjutnya adalah menggunakan XPath untuk mencari elemen <a> yang mengandung informasi agen. Jika elemen ditemukan, tahap selanjutnya adalah menggunakan XPath pada elemen tadi untuk mengekstrak nama dan URL ke agen tersebut.
Setelah nama agen didapatkan, selanjutnya kita akan mengekstrak informasi kontak nomor telepon. Setelah itu, kita bisa menggunakan metode yang sama seperti sebelumnya untuk mengekstrak informasi perusahaan manajer properti.
Ekstrak Waktu Pemutakhiran Data Properti
| |
Bagian ini adalah data terakhir yang akan kita ekstrak yaitu tanggal perubahan terakhir dari informasi properti ini. Secara umum proses yang dilakukan untuk mengekstrak informasi ini sama seperti proses scraping sebelumnya, perbedaannya adalah kita melakukan konversi nama bulan menjadi angka dan kemudian menggunakan fungsi strptime untuk mengubah tanggal tadi menjadi objek DateTime.
Akhirnya kita sudah selesai membuat scraper Rumah123.com😁 Prosesnya sangat panjang tetapi akhirnya kita bisa mendapatkan data yang kita perlukan. Selanjutnya kita akan coba untuk menjalankan scraper yang sudah kita buat untuk mengunduh data properti di daerah Bogor.
Menjalankan Spider💾
Setelah kita membuat scraper kita bisa mulai melakukan scraping dan mengunduh data listing properti ke komputer kita. Pastikan teman-teman sudah mengikuti semua tutorial di atas dan kode scraping sudah lengkap (teman-teman juga bisa mengakses kode scraping pada GitHub di bagian awal artikel).
Untuk menjalankan proses scraping, buka terminal pada lokasi proyek scrapy, kemudian jalankan perintah berikut.
| |
Setelah teman-teman mengeksekusi perintah di atas, teman-teman akan mendapatkan file rumah123.json di folder yang sama dengan proyek scraper. Jika teman-teman tekan CTRL+C maka proses scraping akan berhenti dan teman-teman bisa melihat hasil scraping-nya.
Sampai di sini teman-teman mungkin menyadari satu hal yaitu proses scraping dilakukan dengan sangat lambat. Hal ini memang dilakukan dengan sengaja, ingat pada bagian konfigurasi kita hanya mengunakan CONCURRENT_REQUESTS = 1 dan DOWNLOAD_DELAY = 3 yang berarti setiap kali satu proses scraping selesai, scrapy akan menunggu selama tiga detik sebelum melanjutkan proses scraping.
Tapi kenapa harus begitu?
Melakukan Scraping secara Masif📈
Pada pembahasan sebelumnya kita sudah berhasil menjalankan proses scraping dan mendapatkan sedikit data pada file JSON, tetapi proses scraping tersebut berjalan dengan sangat lambat dan tentunya untuk website yang bersifat masif, lambatnya proses scraping ini akan menjadi penghalang untuk kita bisa mendapatkan data yang kita butuhkan. Selain itu penulis juga menyatakan bahwa proses lambat tersebut memang sengaja, tapi kenapa?
Resumable Jobs⏯️
Pada contoh sebelumnya kita bisa mengentikan proses scraping dengan cara menekan CTRL+C pada terminal. Kemudian jika kita ingin melanjutkan proses scraping, kita bisa menjalankan perintah yang sama yaitu scrapy crawl rumah123. Tapi tunggu dulu, jika kita perhatikan ketika kita menjalankan perintah yang sama, scrapy akan mengulang proses scraping dari awal dan tidak melanjutkan proses scraping terakhir.
Hal ini tentu merepotkan jika kita ingin melakukan scraping dari website dengan data yang banyak. Seperti pada kasus ini Rumah123 memiliki hingga 1000 halaman listing, jika dalam satu halaman ada 10 properti, artinya Rumah123 memiliki 10.000 properti. Karena proses scraping dapat memakan waktu yang lama, kita ingin agar proses scraping ini dapat dihentikan dan dilanjutkan kapanpun.
Untungnya scrapy mendukung proses seperti ini! Daripada menggunakan perintah scrapy crawl rumah123, kita bisa menggunakan perintah:
| |
Argumen -s JOBDIR=crawls/rumah123 berfungsi untuk memerintahkan scrapy untuk menggunakan sistem jobs dan menyimpan informasi crawl ke dalam folder crawls/rumah123 ketika proses scraping dihentikan menggunakan tombol CTRL+C. Ketika kita ingin melanjutkan proses scraping, kita bisa menggunakan perintah yang sama untuk melanjutkan proses scraping dan kita tidak akan mendapatkan data duplikat pada hasil output JSON.
CAPTCHA🤖
CAPTCHA pasti sudah tidak asing lagi bagi teman-teman, sering kali ketika kita melakukan pendaftaran, login, atau berkomentar ke sebuah web app kita akan diminta untuk melakukan verifikasi CAPTCHA. Salah satu bentuk CAPTCHA yang sering kita kenal adalah reCAPTCHA milik Google yang mengharuskan kita untuk memilih foto yang berisi lampu lalu lintas, sepeda, atau mobil. Tetapi apakah teman-teman tahu apa alasan banyak website menggunakan CAPTCHA?
CAPTCHA memiliki kepanjangan Completely Automated Public Turing test to tell Computers and Humans Apart. Dari kepanjangannya saja sudah jelas bahwa tujuan dari CAPTCHA ini adalah untuk membedakan mana traffic yang masuk ke website merupakan aktivitas manusia atau aktivitas komputer.
Kenapa hal ini perlu kita ketahui ketika membuat sebuah web scraper?
Karena sebagai pemilik website, kita tentunya tidak mau ada yang melakukan abuse pada sistem misalnya melakukan spamming dengan mengirim banyak komentar terus-menerus atau memberikan rating yang banyak untuk meningkatkan visibilitas suatu barang di marketplace.

Hubungan CAPTCHA dengan web scraping adalah proses web scraping merupakan aktivitas bot yang berarti kemungkinan besar scraper yang sudah kita buat tadi akan diblokir oleh website melalui fungsi firewall. Biasanya aktivitas scraping sangat mudah dideteksi dan ditanggulangi bagi pemilik website, cukup dengan mengintegrasikan layanan seperti CloudFlare maka website tersebut akan terlindungi dari bot dan scraper yang secara umum bisa mengakses ratusan halaman dalam hitungan menit.
Inilah salah satu pembeda antara traffic dari manusia/user dan bot, traffic yang dihasilkan oleh manusia biasanya lambat, kita tidak mungkin membuka 100 halaman dalam waktu satu menit dan lanjut buka 100 halaman selanjutnya kan? Maka dari itu pada artikel ini penulis menggunakan concurrency yang rendah untuk menghindari munculnya CAPTCHA pada proses scraping.
| |
Contoh blokir yang dilakukan oleh Rumah123 jika terdeteksi traffic yang terlalu cepat (HTTP 429 Too Many Request). Sumber: Penulis.
Selain dengan menggunakan level concurrency yang rendah, kita juga sudah mengimplementasikan AutoThrottle, plugin ini berfungsi untuk melambatkan proses scraping jika didapatkan server memblokir akses. Tentu cara ini merupakan cara yang naif karena bisa saja IP kita di blokir meskipun sudah menggunakan concurrency yang rendah. Maka dari itu ada banyak cara lain misalnya menggunakan proxy, memutar User-Agent, dan teknik-teknik lain untuk menghindari proteksi website terhadap web scraping. Mengenai detailnya teman-teman bisa cari mengenai trik-trik tersebut di Google ya!
tl;dr; gunakan concurrency yang rendah (1-2 item per detik) dan juga gunakan VPN untuk menghindari IP kita diblokir oleh website tujuan. Selain itu kita juga bisa menggunakan layanan seperti Zyte atau menggunakan rotasi proxy.
Dynamic JS Content ⏳
Sebelum kita membahas mengenai dynamic JS content, kita perlu tau bagaimana website modern bekerja. Kebanyakan website sebelum tahun 2010 umumnya menggunakan server PHP dan proses rendering atau pembuatan struktur website terjadi di sisi server (disebut juga server side rendering (SSR)).
Seiring perkembangan zaman, banyak website mulai mengimplementasikan client side rendering (CSR) yaitu teknik untuk membuat struktur halaman di sisi klien menggunakan JavaScript. Pada pembahasan awal kita tahu bahwa HTML menyatakan struktur website dan struktur tersebut diekspresikan sebagai Domain Object Model (DOM). Apa jadinya jika struktur tersebut tidak tersedia tetapi dibuat secara dinamis pada klien?
Scrapy tentunya tidak akan bisa melakukan scraping karena tidak ada DOM yang bisa dicari karena scrapy tidak memiliki fitur untuk mengeksekusi kode JavaScript untuk menghasilkan konten dinamis seperti halnya peramban/browser.
Solusinya adalah scrapy memiliki integrasi ke dua library untuk menghasilkan output halaman dinamis tersebut. Solusi pertama adalah menggunakan library scrapy-splash untuk melakukan pre-rendering atau dengan menggunakan headless browser dengan library scrapy-playwright. Teman-teman bisa mempelajari mengenai dua library ini pada dokumentasi Scrapy.
Tapi tenang saja teman-teman, sebagian besar website masih mengadopsi SSR, hanya sedikit website yang sudah beralih ke CSR. Jika teman-teman tidak yakin perlu menggunakan teknik pre-rendering atau tidak, coba gunakan scrapy shell untuk melakukan percobaan apakah website yang dituju menggunakan SSR atau CSR.
Penutup👓
Wah panjang sekali ya perjalanan kita untuk membuat satu web scraper🥲
Kita sudah belajar mengenai bagaimana sebuah website dapat dibangun menggunakan HTML, CSS, dan JS dan bagaimana kita bisa memanipulasi Document Object Model (DOM) menggunakan XPath dan CSS selector untuk memilih elemen-elemen HTML yang mengandung data untuk kita scraping.
Selain itu kita sudah belajar menggunakan scrapy untuk dapat membuat sebuah web scraper Rumah123 dan menyimpan data properti rumah di daerah Bogor. Kita juga sudah membahas bagaimana cara melakukan scraping secara masif dengan menggunakan resumable jobs dan kendala yang bisa kita temui seperti CAPTCHA dan dynamic JS content.
Sampai di sini dulu perjalanan kita, di artikel selanjutnya kita akan menggunakan dataset yang sudah kita kumpulkan melalui scraping ini untuk melakukan prediksi harga rumah.
Stay tuned!
Referensi📚
- “Getting started with the web - Learn web development | MDN.” Diakses: 14 Januari 2024. [Daring]. Tersedia pada: https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web
- “CSS Selectors Reference.” Diakses: 14 Januari 2024. [Daring]. Tersedia pada: https://www.w3schools.com/cssref/css_selectors.php
- “CSS selectors - Learn web development | MDN.” Diakses: 14 Januari 2024. [Daring]. Tersedia pada: https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Selectors
- “XPath Syntax.” Diakses: 14 Januari 2024. [Daring]. Tersedia pada: https://www.w3schools.com/xml/xpath_syntax.asp
- “Scrapy | A Fast and Powerful Scraping and Web Crawling Framework.” Diakses: 14 Januari 2024. [Daring]. Tersedia pada: https://scrapy.org/
- F. Noor Fiqri, “Pemodelan Daerah Potensial Pertanian di Indonesia sebagai Usaha Restorasi Ekonomi pada Masa Pandemi COVID-19 menggunakan Metode Hierarchical Clustering.” Zenodo, September 2020. doi: 10.5281/zenodo.10526308.
- “Scrapy 2.11 documentation — Scrapy 2.11.0 documentation.” Diakses: 20 Januari 2024. [Daring]. Tersedia pada: https://docs.scrapy.org/en/latest/