
Foto sampul oleh Giuli Canderle dari Unsplash
Klasifikasi merupakan salah satu kegiatan yang paling sering dilakukan menggunakan machine learning. Pada artikel ini kamu akan mencoba untuk membuat sebuah model untuk melakukan klasifikasi pada spesies bunga iris (Fisher, 1936). Bunga iris memiliki tiga spesies, yaitu: versicolor, virginica, dan setosa. Dataset yang digunakan berisi informasi panjang dan lebar untuk masing-masing kelopak pada bunga (sepal dan petal). Klasifikasi yang akan kita buat ini termasuk ke dalam jenis multiclass classification, karena terdapat lebih dari dua kelas output.
Dataset ini merupakan dataset standar yang biasa digunakan untuk belajar machine learning, mirip seperti Hello World saat kamu pertama kali belajar membuat program. Dataset ini berisi 150 data tanpa adanya data kosong dan merupakan dataset yang paling banyak digunakan dalam pembelajaran machine learning. Dataset ini dapat diakses pada UCI Machine Learning Repository.
Selain itu, kamu juga akan belajar bagaimana melakukan data ingestion, exploratory data analysis, preprocessing, training, dan juga evaluation menggunakan dataset ini. Perlu diingat bahwa tidak semua proses EDA dan preprocessing diperlukan untuk melakukan analisis, tetapi dipilih sesuai dengan jenis data yang kamu olah.
Karakteristik dataset:
- Kelas output seimbang (banyaknya kelas seragam untuk tiga kelas output).
- Tidak terdapat data kosong.
- Data tersebar membentuk cluster.
- Outlier tidak signifikan.
Catatan! Tidak semua dataset akan memberikan informasi ini. Kalau kamu punya data mentah, kamu harus melakukan EDA untuk mengetahui distribusi dan sebaran data. Selain itu, informasi tersebut juga akan berguna untuk melakukan preprocessing. Dengan adanya informasi ini, kamu tidak perlu melakukan EDA yang terlalu intensif.
K-Nearest Neighbor🤼
K-Nearest Neighbor merupakan algoritma untuk melakukan klasifikasi dengan cara membandingkan jarak ketetanggaan tiap-tiap titik data dengan data yang akan diprediksi. Pada algoritma ini metode jarak yang digunakan biasanya adalah jarak Euclidean. Data baru akan dibandingkan jarak terdekat dengan tetangganya, semakin banyak tetangga dengan jarak yang dekat, maka data tersebut akan masuk ke dalam kelas tersebut.
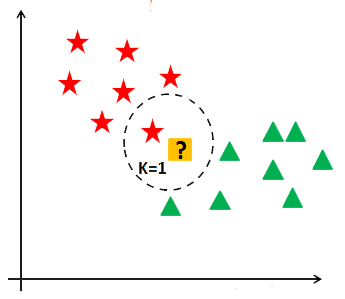
Banyaknya tetangga yang akan menjadi penentu kelas data yang baru, ditentukan oleh nilai konstanta \(k\). Nilai ini bisa ditentukan secara bebas atau dengan melakukan training menggunakan beberapa nilai \(k\) hingga mendapatkan akurasi tertinggi atau mean absolute error (MAE) paling kecil.
Contoh Klasifikasi Manual🖊
Terdapat data pengukuran berat badan dan tinggi badan sebagai berikut. Tentukan apakah berat badan 80 kg dengan tinggi badan 150 cm termasuk normal atau obesitas dengan menggunakan algoritma KNN dengan \(k=3\).
| Berat Badan | Tinggi Badan | Kelas |
|---|---|---|
| 70 | 200 | Normal |
| 68 | 173 | Normal |
| 90 | 150 | Obesitas |
| 100 | 170 | Obesitas |
Jawab Buat tabel jarak antara data baru dengan data yang ada, pada contoh ini kita akan menggunakan jarak Euclidean. Setelah jarak antar data didapatkan, urutkan berdasarkan jarak terkecil kemudian ambil data teratas.
Persamaan jarak Euclidean yaitu:
$$ d(x,y) = \sqrt{ {(x_2-x_1)}^2 + {(y_2-y_1)}^2 } $$dengan \(x\) dan \(y\) adalah dua titik pada ruang Euclidean yang akan diukur.
Contoh Jarak antara berat badan \(x_1=70\) dan tinggi badan \(y_1=200\) dengan berat badan \(x_2=80\) dan tinggi badan \(y_2=150\).
$$ \begin{aligned} d(x,y) &= \sqrt{ {(x_2-x_1)}^2 + {(y_2-y_1)}^2 } \\ &= \sqrt{ {(80-70)}^2 + {(150-200)}^2 } \\ &= 50,99 \end{aligned} $$Lakukan proses yang sama antara semua baris pada dataset dengan data yang akan diuji.
| Berat Badan | Tinggi Badan | Kelas | Jarak (\(d\)) |
|---|---|---|---|
| 90 | 150 | Obsesitas | 10,00 |
| 100 | 170 | Obsesitas | 28,28 |
| 62 | 180 | Normal | 34,98 |
| 70 | 200 | Normal | 50,99 |
Setelah data jarak didapatkan, kemudian urutkan jarak berdasarkan nilai terkecil ke terbesar. Selanjutnya hitung banyaknya data dengan kelas outputnya.
Karena data memiliki dua tetangga dengan kelas obesitas dan hanya satu tetangga dengan data normal, maka data tersebut termasuk ke dalam kelas obesitas. Jika banyaknya kelas sama, maka akan diambil kelas dengan jarak terkecil.
Klasifikasi KNN menggunakan Python🐍
Untuk setiap kode pada artikel ini, salin kode tersebut sebagai sebuah sel pada Jupyter Notebook atau Google Colab!
Untuk membuat sebuah model klasifikasi ini, kita akan melakukan beberapa proses, yaitu:
- Data ingestion
- Membaca data dari file CSV.
- Exploratory data analysis
- Statistik deskriptif data.
- Sampel data teratas.
- Pair plot distribusi data.
- Preprocessing
- Memisahkan features dan label.
- Membagi data latih dan uji.
- Label encoding.
- Standarisasi data.
- Menentukan nilai $k$ berdasarkan mean absolute error.
- Training, menggunakan algoritma KNN.
- Evaluation, menggunakan confusion matrix.

Data Ingestion
Sebelum dapat membaca data, kita perlu mengimpor library yang akan digunakan. Pada artikel ini kita akan menggunakan library NumPy, Pandas, Matplotlib, Seaborn, dan Scikit-Learn. Kelima library ini digunakan untuk membaca, mengolah, dan melakukan training model
| |
Setelah mengimpor library yang akan digunakan, selanjutnya kamu akan membaca file CSV dengan memanggil fungsi read_csv. Data yang dibaca akan disimpan sebagai objek DataFrame. Objek DataFrame ini akan menampung data seperti sebuah tabel. Kamu dapat melakukan berbagai pengolahan data pada objek DataFrame ini.
| |
Exploratory Data Analysis
Setelah kamu memuat data yang akan diolah sebagai DataFrame, kammu dapat mulai melakukan eksplorasi data. Proses eksplorasi data yang akan dilakukan yaitu menghitung statistika deskripsi data, melihat sampel data teratas, dan melakukan visualisasi sebaran data dan distribusinya.
Statistik Deskriptif Data
| |
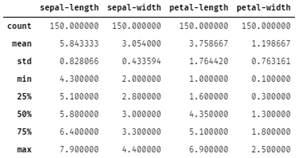
Dapat dilihat pada output di atas masing-masing kelas terdapat 150 data. Semua atribut memiliki mean dan standar deviasi yang berbeda-beda pula. Jika kita melihat pada min dan max, terlihat bahwa range antar atribut juga bervariasi.
Karena kamu akan menggunakan model KNN, maka data perlu di standarisasi sebelum digunakan untuk melakukan training. Hal ini karena KNN menggunakan prinsip metrik jarak dengan Euclidean. Apabila terdapat data dengan range yang jauh, maka dengan melakukan standarisasi akan mempercepat proses training dan meningkatkan akurasi model.
Sampel Data
| |
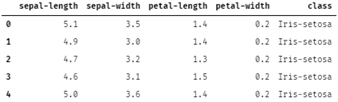
Dari output di atas dapat dilihat ternyata data di dalam file CSV disusun berurutan berdasarkan kelas. Artinya sebelum melakukan training data harus diacak dan dibagi seimbang.
Pair Plot
Pada tahap ini kamu akan membuat pair plot untuk membantu memvisualisasikan hubungan antar variabel pada dataset.
| |
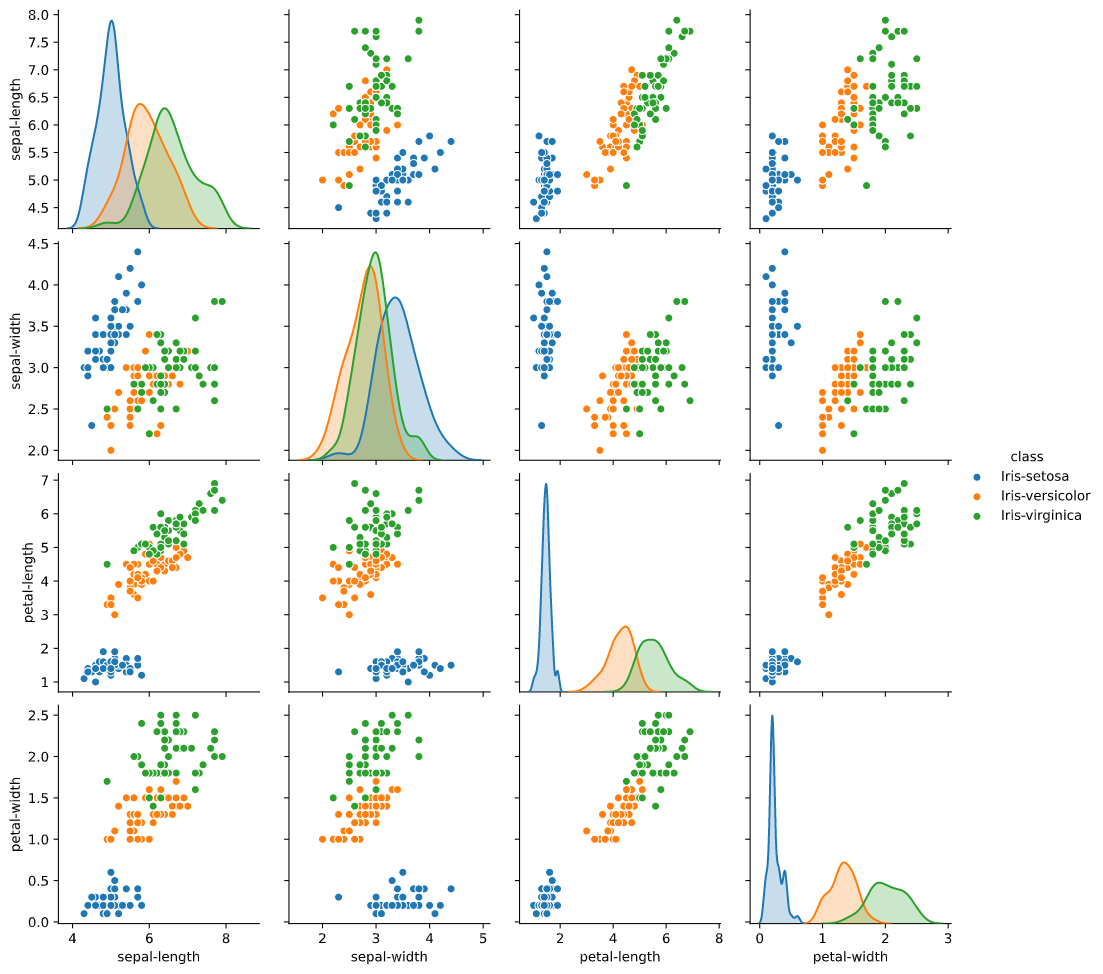
Pair Plot antar Variabel.
Berdasarkan plot yang dibuat, dapat dilihat bahwa kelas iris-setosa selalu terpisah dari kelas yang lain. Artinya saat melakukan klasifikasi terdapat kemungkinan besar bahwa model akan selalu dapat membedakan spesies setosa dengan baik. Dapat dilihat juga distribusi data untuk petal-length, spesies setosa terpisah dari kelas yang lain.
Selain itu, jika dilihat persebaran datanya pada diagram pencar, sebagian besar kombinasi atribut miliki korelasi Pearson yang positif. Artinya features yang terdapat pada dataset ini baik untuk digunakan untuk membuat sebuah model. Selain itu, dengan korelasi yang tinggi, maka model klasifikasi dapat diubah menjadi model regresi untuk melakukan peramalan.
Preprocessing
Memisahkan Features dan Label
Pada tahap ini kamu melakukan operasi slicing untuk membagi data dari dalam objek DataFrame. Pada tahap ini juga kamu akan mengambil data sebagai array, bukan objek DataFrame. Hal ini dilakukan karena library scikit-learn menggunakan tipe data NumPy array untuk digunakan dalam algoritmanya.
| |
Membagi Data Latih dan Uji
Pada tahap ini kamu akan membagi 150 data untuk latih dan uji. Kamu akan menggunakan fungsi train_test_split untuk memudahkan proses pembagian data agar data yang dibagi seimbang.
| |
Label Encoding
Karena kelas dari dataset ini berupa teks, maka perlu dilakukan encoding. Pada kasus ini kamu akan menggunakan label encoding, karena internal algoritma ini menggunakan ketetanggan, maka nilai output tidak akan terbias dari penggunaan teknik encoding ini.
| |
Standarisasi
Algoritma KNN menggunakan metrik jarak (Euclidean), sehingga memiliki data yang terdistribusi merata khususnya pada distribusi normal akan meningkatkan performa model KNN ini. Maka dari itu diperlukan proses standarisasi data.
| |
Menentukan Nilai Konstanta k
Seperti yang sudah di jelaskan sebelumnya, bahwa KNN membutuhkan suatu nilai konstanta $k$ untuk menentukan berapa banyak tetangga yang akan digunakan oleh model. Kode di bawah ini akan melakukan training sebanyak 4o kali dengan nilai $k$ dari 1 hingga 40. Angka 40 ini bersifat bebas dan dapat diganti dengan angka lain.
| |
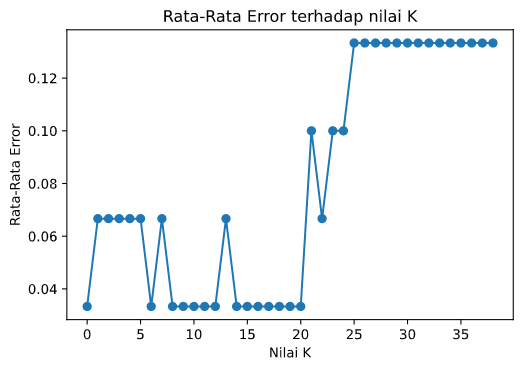
Dapat dilihat pada grafik yang dihasilkan, bahwa terdapat beberapa nilai $k$ yang dapat meminimalisasi nilai error. Contohnya nilai $k$ awal yang digunakan adalah 40, dapat dilihat pada grafik bahwa nilai $k=40$ memiliki tingkat error sebesar 0,17. Ternyata nilai $k$ yang kecil seperti 1, 2, 4, dan 5 memiliki tingkat error yang kecil.
Setelah mengetahui nilai $k$ dengan error yang rendah, kamu dapat melatih kembali model kamu dengan mengubah nilai $k$ sesuai dengan grafik yang ada. Teknik ini merupakan salah satu teknik sederhana untuk menghasilkan model yang lebih baik. Terdapat banyak cara lain untuk meningkatkan akurasi dan performa suatu model yang akan di bahas pada bab selanjutnya.
Training
Pada proses training ini kamu akan menggunakan nilai konstanta $k = 4$. Kamu bisa mengubah angka ini sesuai dengan keinginanmu sesuai pada hasil observasi pada tahap preprocessing sebelumnya.
| |
Evaluation
Setelah proses training, kamu akan mengevaluasi apakah model yang kamu buat memiliki akurasi yang baik atau belum.
| |
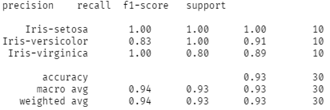
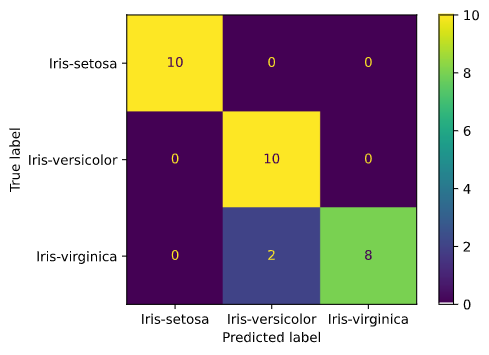
Berdasarkan hasil output dari classification_report, diketahui bahwa model dapat membedakan semua data dengan spesies iris-setosa dengan sempurna. Tetapi pada kelas lain seperti iris-versicolor dan iris-virginica masih terdapat kesalahan klasifikasi yang ditandai dengan precision dan recall yang tidak mencapai angka 1.
Secara keseluruhan model ini berhasil mendapatkan akurasi sebesar 93%. Hasil ini sudah sangat baik melihat juga pada nilai F1 score yang tinggi menandakan bahwa sebaran hasil klasifikasi yang seimbang untuk kelas-kelas lainnya.
| |
Penutup🌌
Sampai di sini kamu sudah belajar tentang algoritma KNN dan contoh pengaplikasiannya untuk melakukan klasifikasi. Latihan selanjutnya kamu bisa mencoba mencari data lain dan melakukan klasifikasi menggunakan algoritma KNN atau algoritma lain yang kamu ketahui.
Klasifikasi bukanlah satu-satunya hal yang dapat dilakukan menggunakan machine learning, masih banyak lagi hal-hal yang dapat dilakukan menggunakan machine learning. Jangan lupa untuk subscribe ke YouTube dan juga ke newsletter Kodesiana.com ya!
Stay tuned, teman-teman!😄
Referensi
- Fisher, R. A. “THE USE OF MULTIPLE MEASUREMENTS IN TAXONOMIC PROBLEMS.” Annals of Eugenics, vol. 7, no. 2, Sept. 1936, pp. 179–88. DOI.org (Crossref), doi:10.1111/j.1469-1809.1936.tb02137.x.
- Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3), 90–95.
- Oliphant, T. E. (2006). A guide to NumPy (Vol. 1). Trelgol Publishing USA.
- Pedregosa, F., Varoquaux, Ga"el, Gramfort, A., Michel, V., Thirion, B., Grisel, O., … others. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12(Oct), 2825–2830.
- Waskom, Michael, et al. Mwaskom/Seaborn: V0.8.1 (September 2017). Zenodo, 2017. DOI.org (Datacite), doi:10.5281/ZENODO.883859.